About The Project
MultiMoCo is a long-term project to build a large-scale multimodal corpus for languages in Taiwan, including the island's four official language groups. The project combines corpus analysis tools, human annotation, and recent multimodal machine learning techniques to create an empirical foundation for supporting and evaluating claims in cognitive linguistics.
Corpus Sources And Annotation Layers
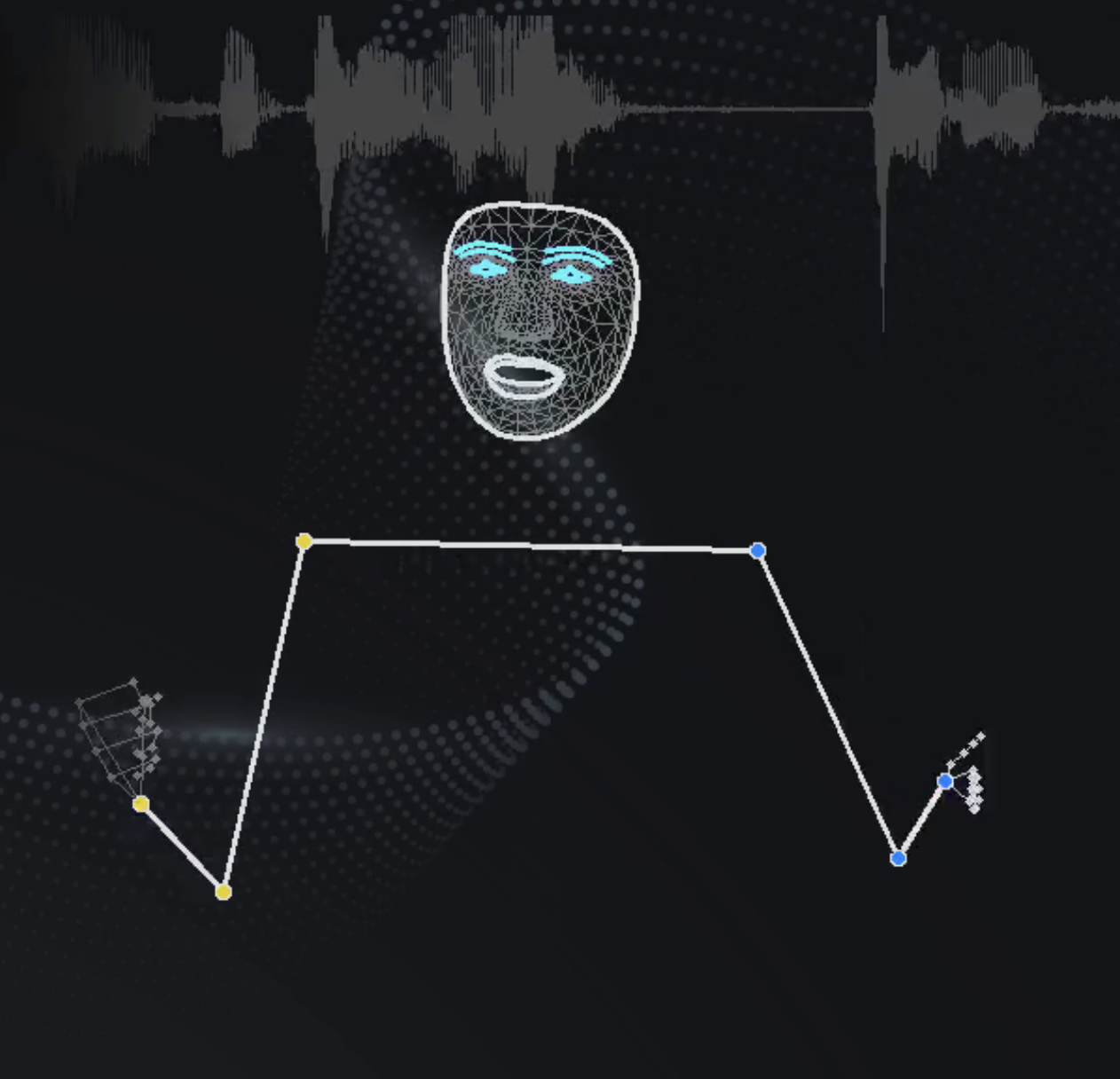
The corpus integrates video data from Taiwan Public Television Service public-channel news and Legislative Yuan proceedings. On top of those recordings, the project builds dialogue transcripts with OpenAI Whisper, extracts on-screen captions with OCR, and identifies speaker gestures with MediaPipe. This layered design allows spoken language, visual text, and gesture to be studied together within one research infrastructure.
Current Public Scale
The current public project statistics report 223 total clips, 5,854 total minutes, 1,485,297 total characters, and 22,805 total gestures. These figures reflect the project's role as a large-scale multimodal resource for empirical research on language use in Taiwan.


