Corpus Linguistics: Pre-Processing
![]()
![]()
Corpus linguistics is firmly rooted in empirical, inductive forms of analysis, relying on real-world instances of language use in order to derive rules or explore trends about the ways in which people actually produce language (as opposed to models of language that rely on made-up examples or introspection).
What software is there to perform linguistic analyses on the basis of corpora? and what can these software do?
Programming (Python, R, etc)
corpus query language.scripting.Data collectionWhat are the tools that are used when compiling and annotating a corpus?
Python.NLTKR
What are the principles that are to take into consideration when compiling and annotating a corpus?
Are there any hard rules regarding how large a corpus ought to be?
For the study of prosody (i.e. the rhythm, stress and intonation of speech), a corpus of 100,000 words will usually be big enough to make generalizations; for the analysis of verb-form morphology (i.e. the use of endings such as -ed, -ing and -s to express verb tenses) would require half a million words. (Kennedy (1998: 68)), while Biber (1993) suggests that a million words would be enough for grammatical studies.
Data preprocessingSGML, XML, LMF, etc)An example taken from the start of a text in the FLOB (Freiberg Lancaster-Oslo/Bergen) corpus of early 1990s British English.

An example of a morpho-syntactically tagged sentence (using the C5 tagset1) taken from the British National Corpus.

Statistics versus Researcher Sensitivity
‘c’est le point de vue qui crée l’objet’ (it is the viewpoint which creates the object), (Saussure).
'Corpus linguistics as a ‘methodology’ rather than a traditional branch of linguistics like semantics, grammar, phonetics or sociolinguistics'. (McEnery and Wilson (1996))
What we have witnessed in the development of corpus linguistics as a discipline is that our chosen methodological standpoint has progressively determined both the object and the aim of the enquiry.
elaborating a reliable methodology to describe and take into account this type of unprecedented evidence.
Shower Presentation Template
Author: Vadim Makeev, Opera Software
Modified: Ramnath Vaidyanthan, for Slidify
library(zipfR)
data(ItaRi.spc)
data(ItaRi.emp.vgc)
summary(ItaRi.spc)
## zipfR object for frequency spectrum
## Sample size: N = 1399898
## Vocabulary size: V = 1098
## Class sizes: Vm = 346 105 74 43 39 25 27 15 ...
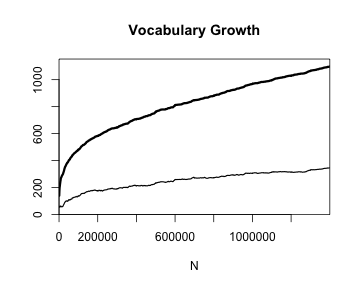
par(mfrow = c(2, 2))
plot(ItaRi.spc)
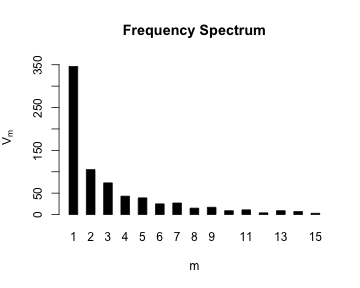
plot(ItaRi.spc, log = "x")
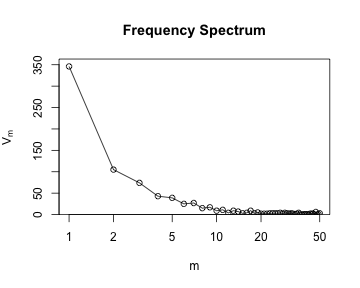
plot(ItaRi.spc, main = "Frequency Spectrum")
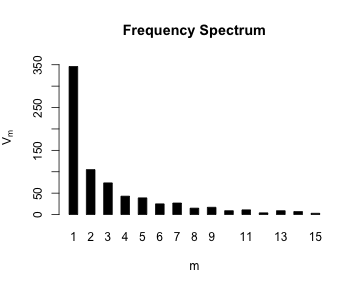
plot(ItaRi.emp.vgc, add.m = 1)